Unleash The Power of Domain Adaptation - How to Train Perfect Segmentation Model on Synthetic Data with HRDA

Tutorial on training accurate and robust Semantic Segmentation model without manual annotation using only synthetic training dataset

Table of Contents
Introduction
This is the final tutorial in the series of posts where we share results of our experiments on leveraging synthetic training data to get the accurate and robust semantic segmentation model on very challenging tasks - cracks segmentation.
- Part 1. How to Train Interactive Smart Tool for Precise Cracks Segmentation in Industrial Inspection
- Part 2. Introducing Supervisely Synthetic Crack Segmentation Dataset
- Part 3. Lessons Learned From Training a Segmentation Model On Synthetic Data
- Part 4. 👉 Unleash The Power of Domain Adaptation - How to Train Perfect Segmentation Model on Synthetic Data with HRDA
In the previous part of this series, we talked about training a model just using synthetic data. We discussed how to improve the crack synthesis method and got results almost as good as a model trained with real data.
In today's tutorial, we're going to boost our results using Domain Adaptation, getting us really close to perfect crack segmentation. At this point, we’re going to add some unlabeled real-life photos of cracks to our pure synthetic data. It is not hard, cause we don’t need to annotate them, anyone can go outside and take some photos of cracks. 😄
Note, that all annotations used for training are auto-generated together with synthetic images. We use manually annotated data only to validate our experiments.
Feel free to follow this guide and the video tutorial to reproduce the results 🚀 on your data.
What is Domain Adaptation?
At its core, Domain Adaptation deals with the challenge of adapting a model that's been trained on one domain (the Source) to perform well on a different but related domain (the Target).
Imagine you train a model on images from a video game, say GTA 5. While the game tries to mimic real-life scenes, there are still differences, especially when you zoom in on the details. Even though GTA 5 has familiar things like cars, roads, and people, the way these images appear can be quite different from real life.
Domain Adaptation helps to bridge these differences during model training, without us having to change the images from the game themselves. And one of the core techniques of Domain Adaptation is Pseudo-labeling.
![Visual difference between two domains: GTA 5 vs. real. [1]](https://cdn.supervisely.com/blog/unleash-the-power-of-domain-adaptation-with-HRDA-synthetic-cracks-segmentation/source_to_target.png?width=800) Visual difference between two domains: GTA 5 vs. real. [1]
Visual difference between two domains: GTA 5 vs. real. [1]
1. Pseudo-Labeling
Pseudo-labeling is a cool trick that comes up in semi-supervised learning and can also be handy for domain adaptation. The idea is that after you train a model on your labeled data, you can use that model to predict labels for your unlabeled data. In that case the model's predictions are called the "pseudo-labels".
Let's break it down: First, you get up your model and train it using your labeled synthetic data. Once it's had some training, you let it guess or "predict" labels for your unlabeled real-world data. These guessed labels are what we call "pseudo-labels". Next, you mix in these pseudo-labeled real images with your original synthetic ones and keep training. As you go along, these pseudo-labels are re-calculated at regular intervals.
![The model is (1) trained on the labeled samples, then this model is used to (2) predict and assign pseudo-labels for the unlabeled samples. Then the distribution of the prediction scores is used to (3) select a subset of pseudo-labeled samples. Then a new model is (4) re-trained with the labeled and pseudo-labeled samples. This process is (5) repeated by re-labeling unlabeled samples using this new model. [2]](https://cdn.supervisely.com/blog/unleash-the-power-of-domain-adaptation-with-HRDA-synthetic-cracks-segmentation/pseudo-labels-cycle.png?width=800) The model is (1) trained on the labeled samples, then this model is used to (2) predict and assign pseudo-labels for the unlabeled samples. Then the distribution of the prediction scores is used to (3) select a subset of pseudo-labeled samples. Then a new model is (4) re-trained with the labeled and pseudo-labeled samples. This process is (5) repeated by re-labeling unlabeled samples using this new model. [2]
The model is (1) trained on the labeled samples, then this model is used to (2) predict and assign pseudo-labels for the unlabeled samples. Then the distribution of the prediction scores is used to (3) select a subset of pseudo-labeled samples. Then a new model is (4) re-trained with the labeled and pseudo-labeled samples. This process is (5) repeated by re-labeling unlabeled samples using this new model. [2]
2. Cross-domain Mixing
Many Domain Adaptation methods use some kind of domain mixing. The idea reminds data augmentations. For instance, in DACS[3] (Domain Adaptation via Cross-domain Mixed Sampling) several objects in a source domain image are selected, and the corresponding pixels are cut out and pasted onto an image from the target domain. Let's break it down:
-
Cut & Paste: We randomly select several objects in a source domain image. Then we cut their pixels and paste into an image from the target domain. This way we are creating a new image that has elements from both domains. Think of it as taking a car from a video game screenshot and placing it onto a real-world street image.
-
Generate Pseudo-labels: For labeling this new mixed image, we don't manually annotate it. Instead, we rely on the model's own predictions. First, the original image from the target domain (a real-world street image) is passed through the trained network. The model predicts a label for this, known as a pseudo-label.
-
Combine Labels: The final label for the mixed image is derived by combining the pseudo-labels (from the target domain) with the actual labels from the source domain. This creates a composite label that reflects the contributions from both domains.
![Visualization of DACS mixing. [3]](https://cdn.supervisely.com/blog/unleash-the-power-of-domain-adaptation-with-HRDA-synthetic-cracks-segmentation/dacs.png?width=800) Visualization of DACS mixing. [3]
Visualization of DACS mixing. [3]
3. Mean Teacher
In essence, the Mean Teacher approach provides a form of self-regularization and stability, making the training process more robust against the challenges posed by noisy and incorrect pseudo-labels.
The basic idea behind Mean Teacher is to maintain two copies of the same model:
-
Student Model: Consider the student model as the "learner" in this setup. This model actively trains on the data and updates its weights in every iteration based on the backpropagation algorithm. The student aims to minimize the difference between its predictions and the ground truth labels (or pseudo-labels in the case of unlabeled data).
-
Teacher Model: The teacher model can be visualized as a "guide" or "mentor". Rather than undergoing direct training, it inherits its knowledge from the student model. The weights of the teacher model are an exponential moving average (EMA) of the student's weights. This averaging ensures that the teacher model is less sensitive to the rapid oscillations or fluctuations the student might experience during training. Instead, the teacher represents a more stable and generalized version of the student. At the end of training, this model is used for making predictions.
-
Consistency Loss: Consistency loss is at the heart of the Mean Teacher approach. When an input image is fed to both the student and teacher models, they both produce predictions. The primary objective is to ensure that these predictions are consistent between the two models. Typically, the mean squared difference of the logits produced by both models is used as the consistency loss. This loss guides the training process, ensuring that the student's predictions don't deviate too far from the teacher's.
-
Augmentations: To encourage the student model to explore and learn more robust features, it's provided with augmented versions of the images – these could have augmentations like blurring, brightness adjustments, random crops, and so on. This contrasts with the teacher model, which receives the original, non-augmented images. By doing this, the student learns to be invariant to these augmentations, thus enhancing its generalization.
![Mean Teacher overview. [4]](https://cdn.supervisely.com/blog/unleash-the-power-of-domain-adaptation-with-HRDA-synthetic-cracks-segmentation/ema-teacher.png?width=800) Mean Teacher overview. [4]
Mean Teacher overview. [4]
You can read more about Mean Teacher in the original paper[5].
HRDA
In our experiments we took advantage of HRDA: Context-Aware High-Resolution Domain-Adaptive Semantic Segmentation[6] (github) — an excellent method in Domain Adaptation. It uses the three techniques we’ve discussed before and the additional improvements:
-
Multi-resolution Framework: Most Domain Adaptation methods for semantic segmentation are GPU memory intensive, HRDA addresses this by using two crops of the image. It combines high-resolution crop for fine segmentation details and low-resolution crop for capturing long-range context.
-
Scale Attention Mechanism: HRDA fuses both high-resolution and low-resolution crops using an input-dependent scale attention. The attention learns to decide how trustworthy the low-resolution and the high-resolution predictions are in every image region.
-
Sliding-window Inference: For robust pseudo-label generation, overlapping slide inference is used to fuse predictions from different regions of an image.
![HRDA overview. [6]](https://cdn.supervisely.com/blog/unleash-the-power-of-domain-adaptation-with-HRDA-synthetic-cracks-segmentation/hrda.png?width=800) HRDA overview. [6]
HRDA overview. [6]
HRDA has shown significant performance improvements compared to the previous State-of-the-Art methods. We implemented Applications for HRDA Training and Inference in Supervisely Ecosystem:
Train HRDA
Train HRDA model for segmentation in semi-supervised mode
Training HRDA
We continue the experiments of our previous blog post, now using all the above techniques within the HRDA implementation.
Training data:
- 1,558 synthesized images (labeled)
- 628 real photos of cracks (unlabeled)
- 70 real photos for validation (manually labeled)
We trained Segformer MiT-b5 [7] (which also is trained by the authors of HRDA) for 20,000 iterations, ~5 hours. Here are the training details:
| Hyper-parameter | Value |
|---|---|
| Model | Segformer MiT-b5 |
| Resolution | from 512 to 640, depending on image aspect ratio |
| Number of images | 1,558 synthetic images + 628 real images without annotations |
| Training iterations | 20,000 |
| Batch size | 6 |
| Optimizer | AdamW |
| Weight decay | 1e-4 |
| Learning rate | 1e-4 |
| LR Scheduler | Polynomial with the power of 1.0 (identical to a linear decay) |
| Warmup | 500 iterations |
Results
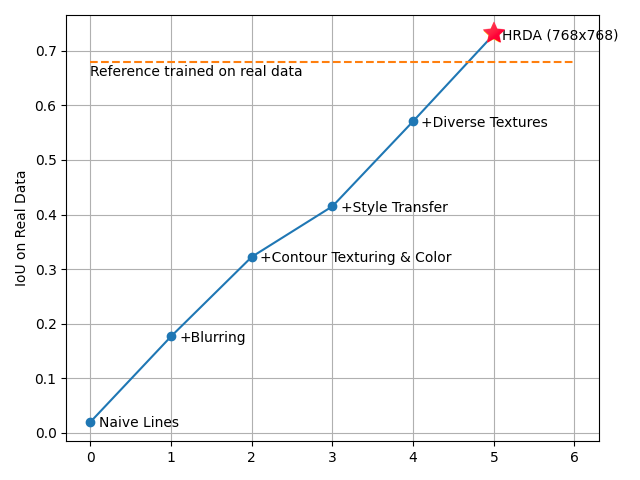
To our surprise, HRDA 🔥 outperformed our Reference model, which trained using real data from 628 annotated crack photos.
 Results
Results
This outcome makes sense given the Reference model is based on the smaller Segformer b3 variant, whereas HRDA uses Segformer b5 with larger number of trainable parameters. Additionally, HRDA employs advanced methods like sliding-window inference and multi-resolution scaling which further enhance its performance.
HRDA Predictions on unseen images




Also, HRDA is much more robust to unseen data compared to the Reference model. This makes HRDA a good model for the inference in-the-wild, when the data comes in with noise or under the unusual circumstances:



Conclusion
In this post, we've explored the core methods in Domain Adaptation and found HRDA to be particularly effective. Through the experiments with training using synthetic data for crack segmentation, Domain Adaptation not only improved prediction accuracy but also enhanced performance on unseen data, making the model more reliable for in-the-wild applications. Impressively, our domain-adapted model even outperformed the Reference model, which was trained solely on real data, proving the value of domain adaptation techniques.
References
-
Learning to Adapt Structured Output Space for Semantic Segmentation
-
Curriculum Labeling: Revisiting Pseudo-Labeling for Semi-Supervised Learning
-
HRDA: Context-Aware High-Resolution Domain-Adaptive Semantic Segmentation
-
SegFormer: Simple and Efficient Design for Semantic Segmentation with Transformers
Supervisely for Computer Vision
Supervisely is online and on-premise platform that helps researchers and companies to build computer vision solutions. We cover the entire development pipeline: from data labeling of images, videos and 3D to model training.
The big difference from other products is that Supervisely is built like an OS with countless Supervisely Apps — interactive web-tools running in your browser, yet powered by Python. This allows to integrate all those awesome open-source machine learning tools and neural networks, enhance them with user interface and let everyone run them with a single click.
You can order a demo or try it yourself for free on our Community Edition — no credit card needed!
Liked this blog post? Share it!





Subscribe to new blog posts
Table of Contents
🤖 Try Supervisely: it's free!
Full stack platform with hundreds of Apps ready to solve any computer vision task: from labeling to model training. Create account



