Introducing MLOps Workflow and Data Versioning: track your datasets, models and Computer Vision experiments

Easy-to-use visual MLOps Pipelines simplify data version control and the ML modeling process, making all experiments reproducible and clear.

Table of Contents
Introduction
In this blog post, you'll learn how to use new MLOps tools for data versioning, experiment tracking, and model management on the Supervisely platform. With Supervisely's MLOps Workflows, you can visualize all data evolution, track how data was modified by different apps and operations, and manage neural network checkpoints, training, and evaluation dashboards—all in a single place.
MLOps in computer vision focuses on enhancing the efficiency and reliability of model development by integrating tools that automate data handling, training, and deployment. It enables teams to maintain consistent and scalable workflows, ensuring that computer vision models remain accurate and effective in real-world scenarios.

Why Tracking and Reproducibility are Critical in ML Experiments
Establishing a robust machine learning process within a company is essential for building high-quality models. The label → train → evaluate loop is central to this process, ensuring continuous improvement of the model. Teams upload raw data, which is then annotated by the labeling team, followed by data augmentation and neural network training. After evaluation and review of the reports, additional data is gathered and labeled, and the cycle repeats to enhance the model further.
-
Data evolves over time: As data changes, it’s crucial to track how and when these changes occur to maintain model accuracy.
-
Avoid confusion after multiple iterations: With each cycle, it becomes increasingly difficult to keep track of which datasets and models were used, leading to potential errors.
-
Ensure reproducibility and collaboration: Without proper tracking, it’s nearly impossible to reproduce results or share accurate insights with colleagues after a period of time.
In this process, various teams—annotation specialists, data engineers, ML researchers, and managers—must work together seamlessly. Experiment tracking and data versioning become essential tools to maintain clarity, ensure consistency, and foster collaboration across these diverse groups.
How Data Versioning Enhances the Label → Train → Evaluate Cycle
In the fast-paced world of machine learning, effectively managing data is critical. Having quick access to the following, all in one place and with clear relationships, is essential:
- Datasets and their versions
- Historical data changes and annotations
- Model checkpoints
- Final trained model
- Model evaluation reports
- Experiment logs and configurations
- Model deployment and inference
- Auto-labeling scenarios
Data versioning is a key tool that helps streamline this process, ensuring smooth and efficient workflows.
Imagine you’re starting a new project and need to upload a large dataset. As you work with this data, you might want to run multiple experiments on its original state and keep track of all subsequent changes. This includes storing different stages of data transformations and creating checkpoints or backups at crucial points in the project. Managing these requirements can be daunting, especially with numerous projects running simultaneously.
Spending time on the same actions day after day is likely to harm your productivity, and storing duplicates will require more resources.
Here’s how data versioning addresses these challenges:
- Avoid Redundant Tasks: Data versioning prevents the need for repetitive data uploads by tracking changes and storing versions systematically.
- Reduce Clutter: It eliminates the hassle of managing multiple project duplicates by centralizing version control.
- Simplify Backup Management: With versioning, you don’t need to worry about when to create backups or how to manage them.
- Enable Quick Restoration: You can easily revert to previous data states with a simple click, streamlining the process of handling different data versions.
- Centralized History: All data changes are tracked and described in a single location, providing clear insights into the data’s evolution.
To facilitate these benefits, our platform includes a dedicated Versions tab for each project.
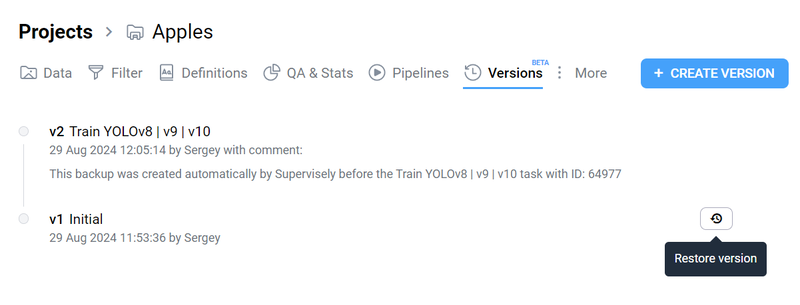 Project Versions tab
Project Versions tab
This feature allows you to:
-
Create and Track Versions: Initiate versioning at the start or whenever changes are made, preserving data integrity without creating unnecessary duplicates.
-
Secure Storage: Store each version in a binary format, protecting against accidental deletion. Each version is uniquely identified and numbered, with media files linked rather than duplicated.
-
Restore with Ease: Restore previous versions by generating a new project version with a click, ensuring you can always access the desired state of the data.
Data versioning optimizes operations by making data management more efficient, organized, and accessible, ultimately boosting productivity and accuracy in machine learning projects.
Pro and Enterprise users of the platform.Visualizing Data Evolution with MLOps Workflows
In collaborative environments, tracking the evolution of data over time is essential for reproducibility and consistency. The Workflow feature provides an intuitive and powerful way to visualize and manage this data evolution, ensuring that experiments are reproducible and models can be retrained with reliable results.
The MLOps Workflow graphically represents the relationship between your data and the applications that process it, offering a clear view of how data flows through your projects.
Here are the types of operations you can perform on data:
- Crate version backups and restore
- Perform data augmentation: cropping, resizing, rotation, blurring, adding noise, etc.
- Label and tag data
- Transform annotations: convert shapes, merge, rasterize, etc.
- Convert famous formats to and from Supervisely
- Split, merge, subsample and filter datasets
- Generate training data
This visual map not only enhances team collaboration but also functions as a version control system, making it easy to manage changes and trace their origins.
With Workflow, you can quickly access key details, such as application sessions, file locations, and direct navigation to relevant projects. The feature is accessible via three convenient entry points: the context menu of a project, task, or workspace, making it easy to integrate into your existing processes.
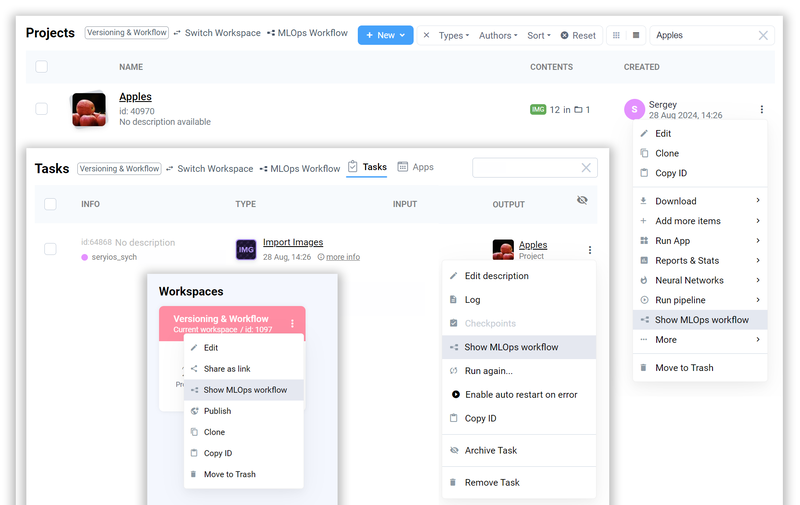 Entry Points into the Workflow
Entry Points into the Workflow
Building a Workflow is straightforward. It centers around tasks involving input and output data, allowing you to document data flow through your projects efficiently.
The project lifecycle begins with data import, and once it's happened, we can immediately view projects Workflow.
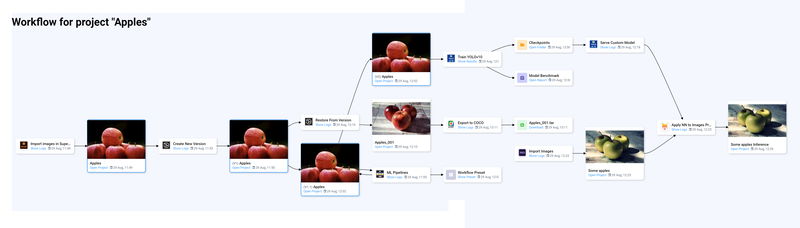 Workflow example
Workflow example
As the project progresses, it undergoes various transformations. In this example, initially, data was annotated using the Image Labeling Tool with the help of the Smart Tool, integrated with the Segment Anything Model 2 for semi-automatic object segmentation. A project version (v1) was created to capture this state before data modifications in ML Pipelines. The Workflow graphically shows an intermediate project state (v1.1) as a visual representation of changes. Additionally, a preset file was generated in the results of ML Pipelines. This preset not only allows us to review the process that led to the image modifications but also enables us to replicate the process on another project without having to recreate it from scratch.
Model training with Train YOLOv10 also created a new project version (v2), capturing the state during training—this is an automated process for the Train Apps. These types of apps typically generate checkpoint files and benchmark reports that evaluate the model's performance across various metrics such as mAP, Precision, Recall, and Inference Speed.
Following training, the model was applied to new datasets for object detection tasks. Additionally, a team member exported version (v1) in COCO format to share with collaborators using different platforms.
By integrating versioning and workflows into your applications, you can enhance data management efficiency, making collaboration and project tracking more effective.
Benchmark Reports for Effective Model Performance Evaluation
Data evaluation within the context of versioning and workflow features provides a robust framework for assessing and tracking model performance over time. By leveraging the app session data, you can thoroughly evaluate how changes in model architecture, hyperparameters, or datasets affect performance, ensuring that every iteration moves the project closer to the desired outcome.
In addition, the model benchmark reports generated within this framework offer a detailed analysis of various performance metrics such as mAP, Precision, Recall, IoU, Classification Accuracy, Calibration Score, and Inference Speed.
These metrics provide a comprehensive view of the model's capabilities, highlighting strengths and areas for improvement.
The ability to review these reports across different versions enables a deeper understanding of how the model evolves, ensuring that any modifications lead to tangible improvements. This systematic approach to data evaluation, facilitated by versioning and workflow integration, is crucial for optimizing model performance and achieving consistent, reliable results in machine learning projects.
Enhancing Your Applications with Workflow Functionality
Integrating Workflow functionality into your applications on the platform can significantly enhance their capabilities. To ensure you are utilizing the latest features and improvements, always work with the most recent versions of the platform and SDK.
For comprehensive guidance on integrating these functionalities, please refer to the technical documentation available on the Supervisely Developer Portal: MLOps Workflow Integration. This resource provides detailed instructions for incorporating Workflow features into your custom applications.
When designing your Workflows, keep the following best practices in mind to maintain clarity and usability:
- Leverage Projects Over Datasets: Instead of creating individual cards for each dataset, use project cards to consolidate related datasets, improving workflow readability.
- Use Folder Cards for Archives: Replace multiple File cards with a single Folder card for related work, naming the source folder in team Files to reflect the current task.
- Incorporate Descriptions: Utilize description fields in customization settings to provide additional context and clarity.
- Modify Main Node Titles Wisely: Alter the title of the main node only when necessary to indicate special operating modes.
- Prioritize Accurate Card Customization: Ensure each card contains precise information relevant to the task at hand for easier workflow interpretation.
- Avoid Overwriting Card States: Prevent confusion by maintaining a clear history of connections without overwriting card states.
- Organize Session-Based Applications: Set up session-based applications to keep workflows orderly and prevent clutter around single tasks.
By adhering to these guidelines, you can create workflows that are both functional and visually intuitive, making them easier to navigate and understand.
Supervisely for Computer Vision
Supervisely is online and on-premise platform that helps researchers and companies to build computer vision solutions. We cover the entire development pipeline: from data labeling of images, videos and 3D to model training.
The big difference from other products is that Supervisely is built like an OS with countless Supervisely Apps — interactive web-tools running in your browser, yet powered by Python. This allows to integrate all those awesome open-source machine learning tools and neural networks, enhance them with user interface and let everyone run them with a single click.
You can order a demo or try it yourself for free on our Community Edition — no credit card needed!
Liked this blog post? Share it!





Subscribe to new blog posts
Table of Contents
🤖 Try Supervisely: it's free!
Full stack platform with hundreds of Apps ready to solve any computer vision task: from labeling to model training. Create account



