XMem + Segment Anything: Video Object Segmentation SOTA | Tutorial

How to segment and track objects on videos automatically with Segment Anything and XMem to build custom training datasets.

Table of Contents
In this tutorial, you will learn how to segment any object on your videos to build a custom training dataset. We will demonstrate the fast and robust video annotation pipeline for the automation of manual video labeling. Here is the list of breakthroughs and advancements that the XMem model provides:
-
XMem offers state-of-the-art performance on long-video datasets while being on par with top methods on short-video datasets.
-
The model tracks objects precisely and predicts masks with high quality.
-
The model runs in real-time and has a small GPU memory footprint even for long videos.
-
XMem works great on really challenging videos, like camera motion, viewpoint change, objects rotation, deformation, scale variation, full and partial occlusion, out-of-view, aspect ratio change and so on.
Video tutorial
We will explain how to combine the following three Computer Vision tools into a single workflow and achieve fast accurate segmentation of objects on videos:
-
Segment Anything model (SAM) to automatically annotate the first frame
-
XMem model to predict the given masks on the next frames
-
Video Labeling toolbox to connect models together and provide interactive user-friendly GUI for labeling automation, manual verification and correction
What is Video Object Segmentation (VOS)?
Video Object Segmentation (VOS) is a computer vision task where the goal is to highlight (segment) all pixels of specific target objects throughout all frames in a given video.
In the computer vision community, this task is often referred to as Semi-Supervised VOS where the user provides the annotation of objects on the first frame and the neural network tracks and segments these objects in all other subsequent frames as precisely as possible.
This approach allows to segment and track any objects on videos even the custom ones. So you can use any class-agnostic model for fast object segmentation (e.g., Segment Anything) for labeling objects of interest on the first frame and then the XMem class-agnostic masks tracking model will segment these objects on the next frames.
What is XMem model?
XMem neural network is a video object segmentation architecture for long videos with unified feature memory stores. The model is class-agnostic which means that it can track masks for any objects. The model can 'memorize' an object and continue to segment it even after the object leaves the video scene for some time. It is also good at handling complex scenes with object occlusions and changes in shape and view.
Check out this great demo video from the authors that illustrates how cool the XMem model is:
XMem offers excellent performance with minimal GPU memory usage for both long and short videos. The model is implemented to deal with both single and multiple objects on long videos. It is the first multi-store feature memory model used for video object segmentation. It was introduced at European Conference on Computer Vision (ECCV) in 2022.
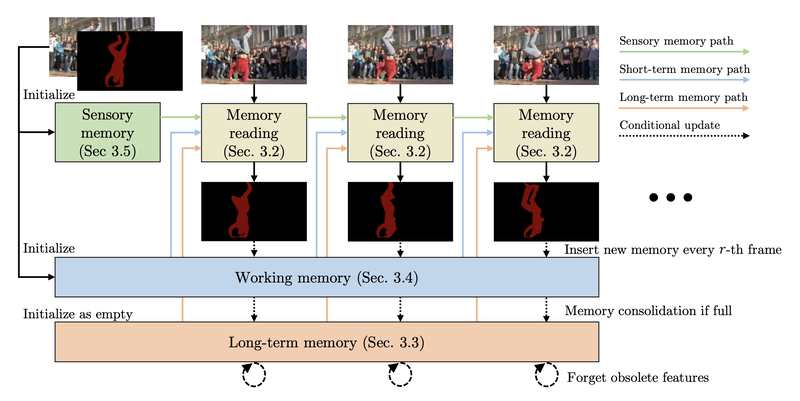 XMem architecture overview. The memory mechanism gets relevant features from all three different types of memory stores and predicts the object mask based on them. The sensory memory updates every frame, and the working memory updates every n-th frame. Long-term memory is a compact representation of the working memory.
XMem architecture overview. The memory mechanism gets relevant features from all three different types of memory stores and predicts the object mask based on them. The sensory memory updates every frame, and the working memory updates every n-th frame. Long-term memory is a compact representation of the working memory.
Step-by-step guide for VOS
Follow the below steps to reproduce the video tutorial for Video Object Segmentation on your data in Supervisely.
Step 0. Connect your GPU to Supervisely
This is a one-time procedure, just skip this step if you already did that.
With a single command executed in the terminal, you can connect your personal computer with GPU to the Supervisely account and run on your machine any apps that require a video card. YOu can connect multiple computers and it will allow you to horizontally scale computational resources for your experiments. To learn more watch this 1.5-minute how-to video.
Step 1. Run Segment Anything model (SAM)

Serve Segment Anything Model
Deploy model as REST API service
In the video tutorial, we deploy and use Segment Anything interactive segmentation model to fast objects segmentation on the first frame. Just run the app, select one of the ready-to-use pre-trained models and pres Deploy button in the GUI.
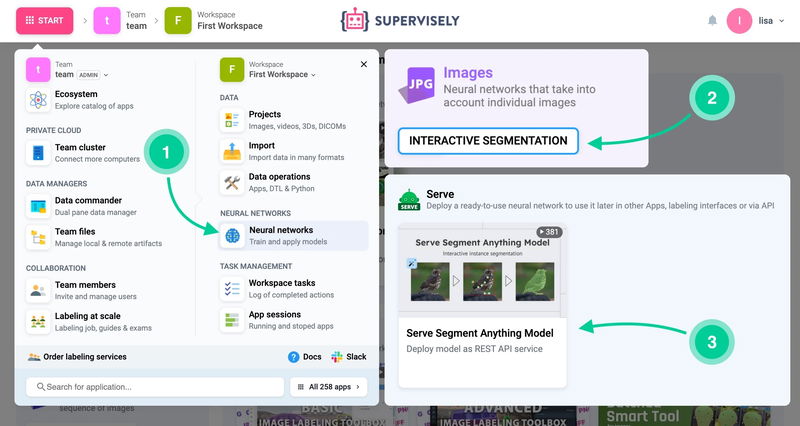 Go to Start → Neural Network → Interactive Segmentation.
Go to Start → Neural Network → Interactive Segmentation.
Interactive segmentation allows users to provide feedback for the model by putting positive and negative points on the image. It helps the model to segment the object inside a bounding box and explicitly control the predictions. Such interaction makes it possible to select an object of interest and correct prediction errors.
The demo video below illustrates how simple and fast it is to segment objects using AI assistance. You can apply any interactive segmentation model either for images or videos in Supervisely.
Enterprise Edition: By default, the administrator of your Supervisely instance deploys one or several interactive segmentation models and makes them available for all users on the instance. If the model has not started yet, just run it yourself or contact your instance administrator.
Step 2. Run XMem model
Run the XMeme serving app on the computer with GPU.
XMem Video Object Segmentation
Semi-supervised, works with both long and short videos
Click Start button → go to Neural Networks page → Video segmentation section and run the XMem model on your computer with GPU:
Step 3. Segment and track objects on videos
Now you can go to the video labeling toolbox, select one or several objects and track selected masks on the next frames.
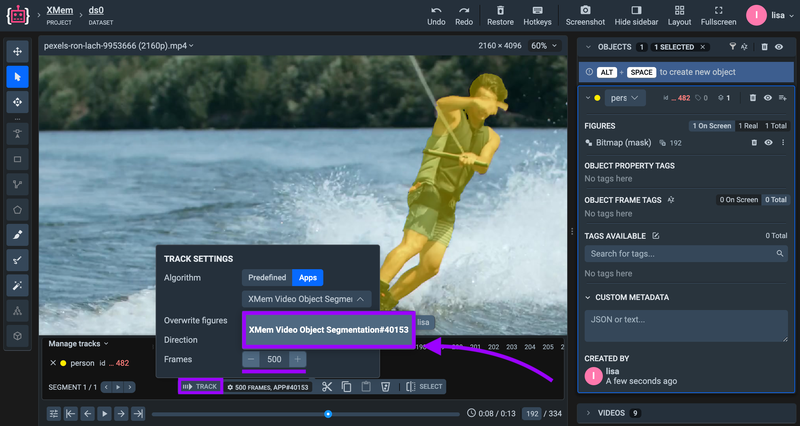 Select the tracking algorithm and press "Track" button on the video timeline.
Select the tracking algorithm and press "Track" button on the video timeline.
Let's check the results
Our experiments confirm that the XMem model performs exceptionally well on a large number of use cases. Its impressive ability to "memorize" objects and accurately segment them on long videos, along with its capacity to handle complex scenes with occlusions and shape changes, makes it a valuable addition to the video labeling toolkit for manual labeling automation.
XMem limitations
Neural network XMem for masks tracking sometimes fails when the target object moves too quickly or has severe motion blur. So even the sensory memory — the fastest memory block in the model architecture cannot catch up with fast object changes. Also, one of the additional failure cases is the fast motion with similarly-looking objects that do not provide sufficient appearance clues for XMem to track.
Conclusion
In this tutorial, you learned how to perform efficient video object segmentation using two state-of-the-art models.
-
The first model — Segment Anything is used to quickly segment objects on the first frame.
-
XMem model is used to track these masks on the next frames.
As you can see, Supervisely Video Labeling Toolbox and the Ecosystem of Apps can help you annotate videos fast for your custom training datasets. Try it yourself in our free Community Edition version.
Supervisely for Computer Vision
Supervisely is online and on-premise platform that helps researchers and companies to build computer vision solutions. We cover the entire development pipeline: from data labeling of images, videos and 3D to model training.
The big difference from other products is that Supervisely is built like an OS with countless Supervisely Apps — interactive web-tools running in your browser, yet powered by Python. This allows to integrate all those awesome open-source machine learning tools and neural networks, enhance them with user interface and let everyone run them with a single click.
You can order a demo or try it yourself for free on our Community Edition — no credit card needed!
Liked this blog post? Share it!





Subscribe to new blog posts
CTO and Founder at Supervisely, PhD in Computer Vision
Table of Contents
🤖 Try Supervisely: it's free!
Full stack platform with hundreds of Apps ready to solve any computer vision task: from labeling to model training. Create account



